

AICCELERATE
The AICCELERATE project intends to build a complete system for scaling up AI-enabled digital solutions for different hospital use cases. The project has ~11 million € budget for 17 partners across Europe.
Health data interoperability is a major challenge for the generalizability and reusability of artificial intelligence models in different healthcare settings. I authored a blog post to give a brief description on this challenge. I am working as a work package leader in AICCELERATE; designing and developing the data interoperability architecture as illustrated in the figure below. The source code of the components that I am working on are open and available on GitHub.
- AICCELERATE Common Data Model based on HL7 FHIR.
- Data Integration Suite which will ingest existing healthcare data of the hospitals and transform to the AICCELERATE Common Data Model. We are building this suite on FAIR4Health Data Curation Tool to make the it scalable and able to process very complex mapping tasks.
- Data Extraction Suite which will work on the HL7 FHIR repository and prepare the health data (which is conforming to the AICCELERATE Common Data Model) for AI algorithms. This suite is designed to act like a feature registry on top of HL7 FHIR using the concepts of the federated machine learning architecture that I developed earlier. Data Extraction Suite is planned to provide an inherent integration with Feast.
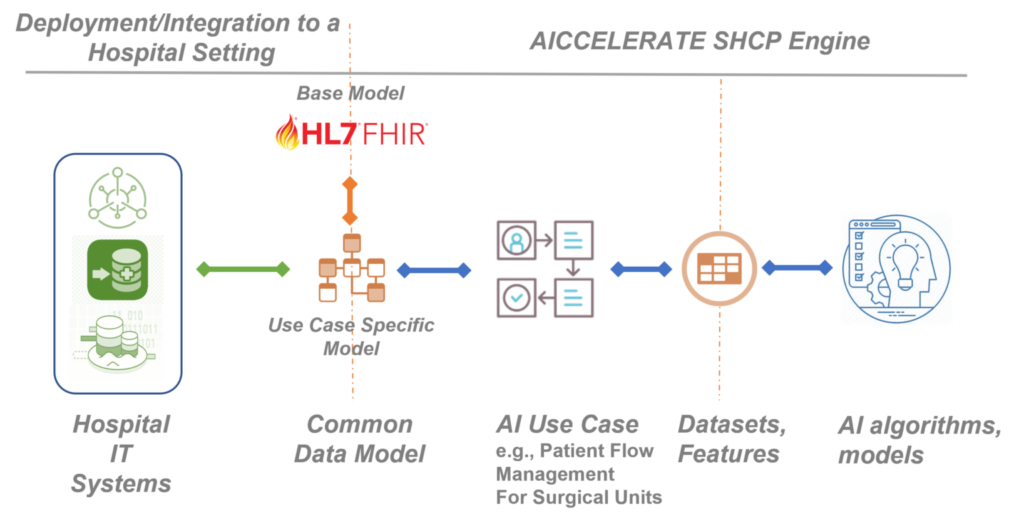
Our health data interoperability architecture is utilizing HL7 FHIR to achieve generalizability, usability and scalability of AI models for digital interventions, clinical decision support and many more in different healthcare settings. We developed the high-performant data processing pipeline with effective use of Apache Spark, Apache Kafka and Akka through a reactive design.
Description
Horizon 2020 (H2020)
January 2021 – April 2024
AI Accelerator – A Smart Hospital Care Pathway Engine